
Most distributed storage systems eventually run into the same uncomfortable tradeoff.
If you want strong consistency, reads stop scaling well.
If you want highly scalable reads, you usually weaken consistency.
Systems like Dynamo and Cassandra embraced eventual consistency largely because coordinating strongly consistent reads across replicas is expensive. Once multiple copies of data exist, making every read observe the latest committed write becomes surprisingly hard.
CRAQ starts from a different question.
What if we could keep strong consistency and scale reads?
That sounds unrealistic at first because distributed systems usually force you to pick one side of the tradeoff.
CRAQ becomes interesting because it doesn’t try to invent an entirely new replication model. Instead, it starts from one of the cleanest replication protocols ever designed: chain replication.
Chain replication is deceptively elegant. Each object is replicated across a linear chain of nodes.
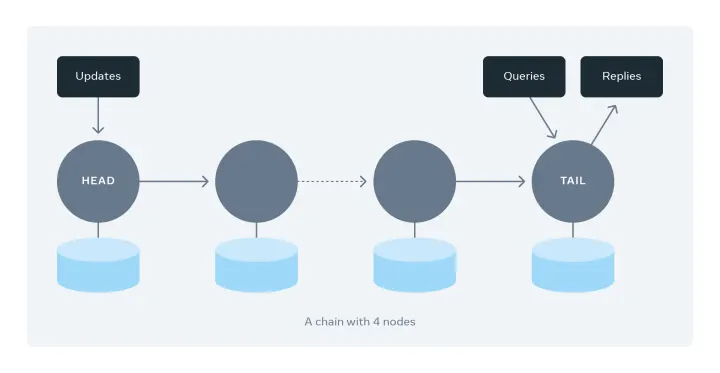
Writes always enter through the head and propagates node by node until it reaches the tail. Only once the tail receives the write is it considered committed.
Reads always go to the tail.
This immediately gives the system something extremely valuable: a globally ordered sequence of writes.
Because the tail only acknowledges writes after seeing them in order, it always contains the latest committed state. So if every read goes there, strong consistency becomes straightforward.
There’s no quorum read logic, no reconciliation, no conflict resolution.
The protocol is surprisingly simple.
It also pipelines writes naturally. Multiple writes can be moving through different parts of the chain simultaneously:
W1 -> N2
W2 -> N1
W3 -> HeadSo write throughput stays high without requiring complex multi-round coordination like Paxos-style systems.
For a while, chain replication almost feels too good. Then reads become the problem.
The issue is not correctness. The issue is that every read is forced onto a single node: the tail.
That means read throughput is fundamentally capped by one machine, no matter how many replicas exist.
Under read-heavy workloads, the tail becomes a bottleneck very quickly and in geo-distributed deployments, things get even worse.
Imagine clients in Europe while the tail is in a US datacenter. Every strongly consistent read now pays a cross-region round trip, even if another replica nearby already has the correct data.
Naturally, the obvious idea is:
Why not allow reads from any replica?
That’s where things break because during replication, different nodes temporarily hold different versions of the object. Something like this is completely normal:
Head: V3
N1: V3
N2: V2
Tail: V2The new write is still propagating.
If clients are allowed to read from arbitrary replicas, some will observe V2 while others observe V3. Strong consistency is gone.
This is the core problem CRAQ tries to solve.
Not replication.
Read correctness during replication.
CRAQ stands for Chain Replication with Apportioned Queries.
The central idea is surprisingly clever.
Instead of treating every replica as either fully safe or unsafe for reads, CRAQ tracks whether the latest version on a node is clean or dirty.
A clean version means the write has already committed at the tail. A dirty version means the node has seen a newer write that has not yet been committed globally. That distinction changes everything.
Suppose a new write V3 is moving through the chain.
Head: [V2, V3-dirty]
N1: [V2, V3-dirty]
N2: [V2]
Tail: [V2]The head and N1 already know about V3, but the tail hasn’t committed it yet.
Now imagine a read reaches N2. N2’s latest version is clean, so it can safely return V2 immediately.
No coordination needed.
Now imagine the read hits N1. N1’s latest version is dirty. At this point, N1 cannot safely return V3 because the write is not committed yet.
But CRAQ also avoids routing the full read to the tail. Instead, N1 sends a lightweight metadata query asking:
What is the latest committed version?
The tail responds with something like:
latest_committed = V2N1 already stores V2 locally, so it simply returns that version. The actual object data never moves from the tail only version metadata does.
That’s the clever part.
CRAQ separates:
- data storage
- commit knowledge
The tail remains the source of truth for commitment ordering, but replicas can still serve data locally.
This has a huge impact on scalability.
In traditional chain replication, every read hits the tail. In CRAQ, most reads never touch the tail at all. Under read-heavy workloads, replicas usually hold clean versions because writes are relatively infrequent compared to reads.
That means reads distribute naturally across the entire chain. The throughput improvement becomes almost linear with chain size.
| Replication Model | Read Scaling |
|---|---|
| Chain Replication | Limited by tail |
| CRAQ | Scales across replicas |
Even under heavy writes, CRAQ still performs better because dirty replicas only issue lightweight version queries instead of forwarding full reads.
The tail handles metadata lookups rather than serving every object directly.
That difference matters a lot.
What makes CRAQ particularly interesting is that it doesn’t force a single consistency model.
Applications can choose.
By default, CRAQ provides strong consistency but it can also expose weaker models. For example, a client can choose to read the newest locally known version even if it’s still dirty.
That means the client may observe slightly stale or temporarily uncommitted data, but latency becomes lower and the system keeps functioning even during failures or partitions.
This flexibility is useful in real systems because not all reads have the same correctness requirements.
A payment system probably wants strict consistency.
An analytics dashboard probably doesn’t.
CRAQ allows both behaviors to exist on the same replication model.
There’s another subtle reason this design works well. Chain replication already gives CRAQ a globally ordered write pipeline. Writes flow strictly head to tail. That means the tail is always the last node to observe a write.
So if the tail says:
V2 is the latest committed version
then every node earlier in the chain is guaranteed to still have V2. This guarantee is what allows replicas to safely serve older committed versions locally. Without ordered propagation, this becomes much harder.
That’s why CRAQ feels less like a completely new system and more like a very smart extension of chain replication.
It preserves the simple write path while fixing the biggest scalability limitation.
What I like most about CRAQ is that it challenges an assumption many distributed systems simply accept.
strongly consistent reads don’t scale well
CRAQ doesn’t completely eliminate that tradeoff. The tail still remains the authority for commitment ordering. But it dramatically reduces how much the system depends on the tail for serving actual read traffic.
And it does this without introducing extremely complicated coordination machinery.
That’s what makes the design elegant.
It doesn’t fight the realities of distributed systems. It carefully rearranges where coordination happens.
And that’s why CRAQ still feels like one of the most underrated distributed storage papers.